03. Crawler Configuration
Step 1. Crawler Configuration
Looking closely at the code repo that was shared with you, it's clear that the web crawler app reads in a JSON file to determine how it should run. Let's look an example of such a file:
JSON Configuration Example
{
"startPages": ["http://example.com", "http://example.com/foo"],
"ignoredUrls": ["http://example\\.com/.*"],
"ignoredWords": ["^.{1,3}$"],
"parallelism": 4,
"implementationOverride": "com.udacity.webcrawler.SequentialWebCrawler",
"maxDepth": 10,
"timeoutSeconds": 2,
"popularWordCount": 3,
"profileOutputPath": "profileData.txt"
"resultPath": "crawlResults.json"
}startPages- These URLs are the starting point of the web crawl.ignoredUrls- A list of regular expressions defining which, if any, URLs should not be followed by the web crawler. In this example, the second starting page will be ignored.ignoredWords- A list of regular expressions defining which words, if any, should not be counted toward the popular word count. In this example, words with 3 or fewer characters are ignored.parallelism- The desired parallelism that should be used for the web crawl. If set to 1, the legacy crawler should be used. If less than 1, parallelism should default to the number of cores on the system.implementationOverride- An explicit override for which web crawler implementation should be used for this crawl. In this example, the legacy crawler will always be used, regardless of the value of the "parallelism" option.If this option is empty or unset, the "parallelism" option will be used (instead of the "implementationOverride" option) to determine which crawler to use. If this option is set to a non-empty string that is not the fully-qualified name of a class that implements the
WebCrawlerinterface, the crawler will immediately fail.maxDepth- The max depth of the crawl. The "depth" of a crawl is the maximum number of links the crawler is allowed to follow from the starting pages before it must stop. This option can be used to limit how far the crawler drifts from the starting URLs, or can be set to a very high number if that doesn't matter.Example: Suppose your starting page "A", links to the following web pages, and you want to run with a depth of 2.
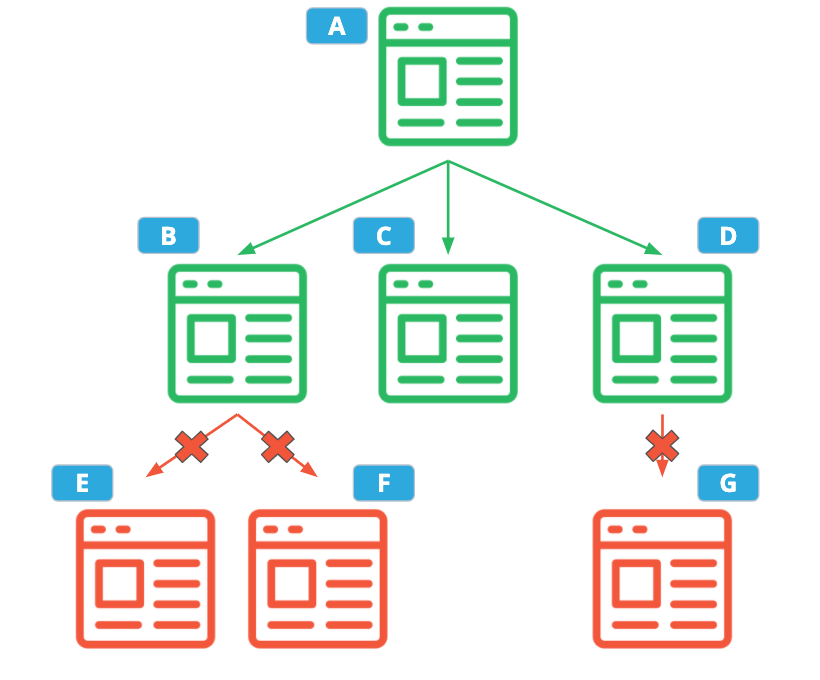
In This Example, Your Crawler Would Only Visit Pages A, B, C, and D
timeoutSeconds- The max amount of time the crawler is allowed to run, in seconds. Once this amount of time has been reached, the crawler will finish processing any HTML it has already downloaded, but it is not allowed to download any more HTML or follow any more hyperlinks.popularWordCount- The number of popular words to record in the output. In this example, the 3 most frequent words will be recorded. If there is a tie in the top 3, word length is used as a tiebreaker, with longer words taking preference. If the words are the same length, words that come first alphabetically get ranked higher.profileOutputPath- Path to the output file where performance data for this web crawl should be written. If there is already a file at that path, the new data should be appended. If this option is empty or unset, the profile data should be printed to standard output.resultPath- Path where the web crawl result JSON should be written. If a file already exists at that path, it should be overwritten. If this option is empty or unset, the result should be printed to standard output.
Implementing Crawler Configuration
Everything you need to read the configuration file is in the com.udacity.webcrawler.json package. In fact, a Java representation of the configuration, CrawlerConfiguration, has already been implemented!
Your task is to fill in the src/main/java/com/udacity/webcrawler/json/ConfigurationLoader.java file:
public static CrawlerConfiguration read(Reader reader)- Implement this first.The
readerparameter contains JSON input. Yourread(Reader reader)method should read the JSON input and parse it into aCrawlerConfigurationusing the Jackson JSON library. This library has already been included in the project dependencies, so you should be able to import classes fromcom.fasterxml.jacksonwithout any additional steps.First, "tell" Jackson that
CrawlerConfigurationuses the builder pattern by annotating theCrawlerConfigurationclass with the@JsonDeserializeannotation:@JsonDeserialize(builder = CrawlerConfiguration.Builder.class) public final class CrawlerConfiguration { ...Next, define the mapping between JSON property names and builder methods by annotating each of the builder's setter methods with
@JsonProperty. For example:@JsonProperty("startPages") public Builder addStartPages(String... startPages) { ...Finally, implement
CrawlerConfiguration#read(Reader)by creating a newcom.fasterxml.jackson.databind.ObjectMapperand callingObjectMapper#readValue.public CrawlerConfiguration load()- Implement this next.Your
load()method will read the JSON string from a filePathwhich has already been provided to theConfigurationLoaderconstructor. Pass that string to theread(Reader reader)and return the createdCrawlerConfiguration. Remember to close the file when you are done!
Finally, make sure the configuration unit tests pass by running them in the terminal:
mvn test -Dtest=ConfigurationLoaderTestHint: If you get a "Stream closed" failure in the test, try calling ObjectMapper#disable(Feature) to disable the com.fasterxml.jackson.core.JsonParser.Feature.AUTO_CLOSE_SOURCE. This prevents the Jackson library from closing the input Reader, which you should have already closed in ConfigurationLoader#load().